
Copilot, Cursor, and ChatGPT generate WordPress PHP that compiles, passes linting, and looks production-ready. The breakdown happens at the maintenance layer: without enforced project-level rules, every developer's AI agent produces structurally different output, and 55% of engineering leaders report their teams are losing shared understanding of how codebases evolve.
TL;DR: AI code generation tools produce functional WordPress code that's individually correct but collectively incoherent. When multiple developers on a white-label team each use different AI assistants with different prompts, the resulting codebase becomes a patchwork of conflicting patterns that balloons maintenance costs across every client site.
What AI Generators Actually Produce in WordPress
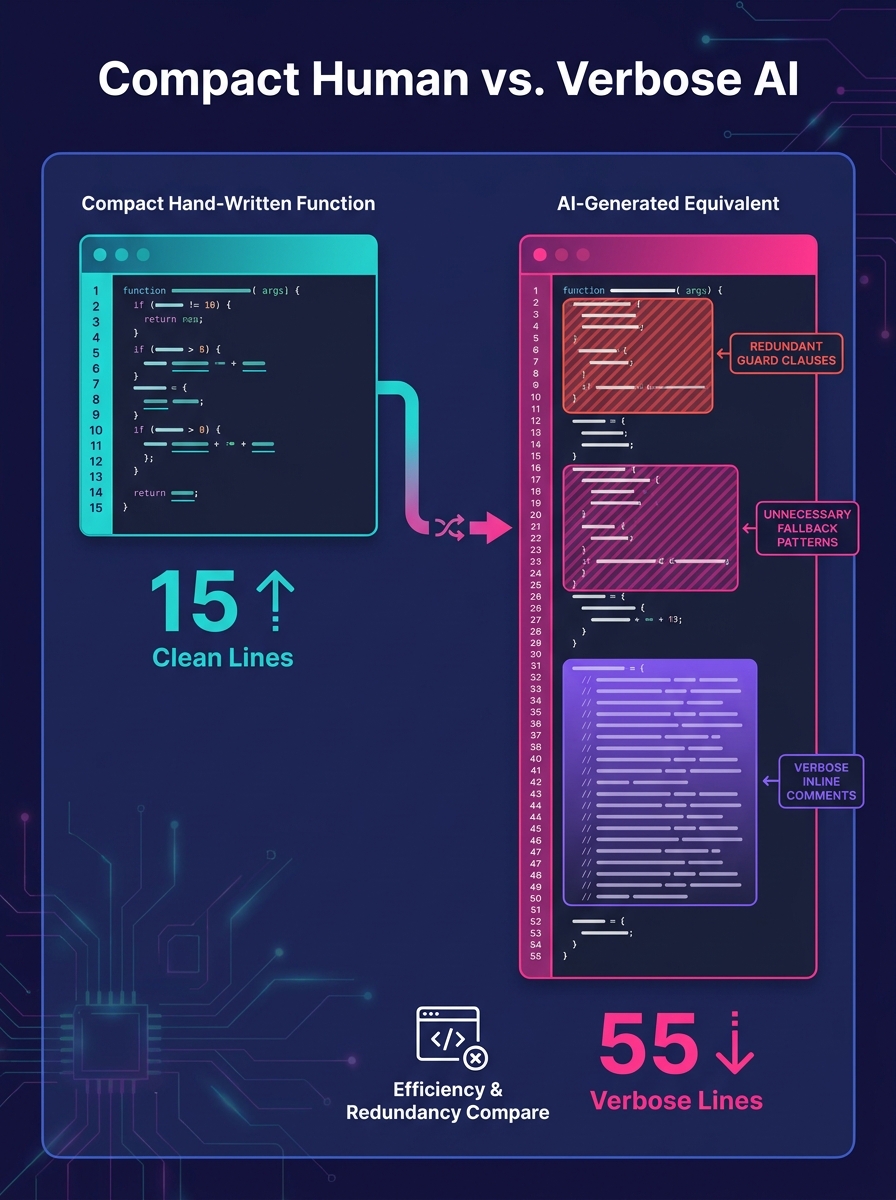
AI code assistants write WordPress PHP the way a cautious contractor pours concrete—thick, defensive, and over-reinforced. The WordPress.com AI builder, for example, generates defensive code with unnecessary markup, heavy JavaScript frameworks, and poor optimization. The output works. It also weighs about three times what a senior developer would ship for the same functionality.
The pattern holds across tools. Ask Copilot to build a custom post type registration function, and it produces 40-60 lines where an experienced WordPress developer writes 15-20. The extra lines aren't wrong. They're guard clauses, redundant capability checks, and fallback patterns pulled from the model's training data. Each line is individually defensible. Stacked across an entire theme or plugin, they create a codebase where simple changes require reading through layers of protective scaffolding that nobody on your team wrote intentionally.
This happens because AI models optimize for correctness in isolation. They have no awareness of what the rest of your project looks like, what patterns your team agreed on last Tuesday, or whether the function they're writing duplicates logic that already exists three files away.
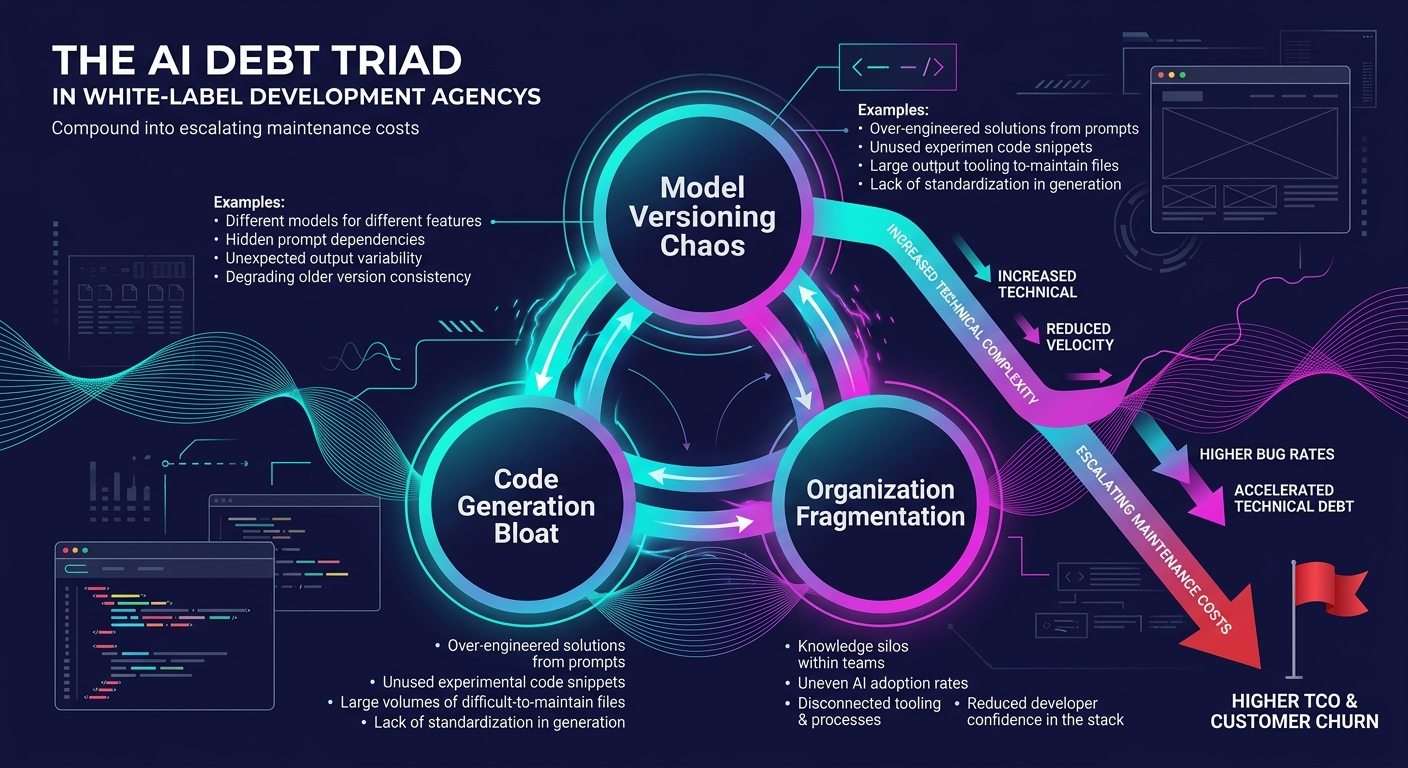
The AI Debt Triad
Why does AI-generated WordPress code accumulate technical debt faster than human-written code? Security researcher Bildea identified three vectors in a report covered by InfoQ: model versioning chaos, code generation bloat, and organization fragmentation. Together, they form what we call the AI Debt Triad, and each vector amplifies the other two.
Model versioning chaos hits white-label agencies hardest. Your senior developer runs Copilot on GPT-4o. Your junior developer uses Cursor with Claude. Your white-label partner uses ChatGPT with a custom system prompt. Each tool generates syntactically valid WordPress code with fundamentally different architectural assumptions. One prefers procedural hooks. Another defaults to class-based wrappers. A third generates closures. The code merges, and now your theme has three distinct paradigms for doing the same thing.
Code generation bloat is the markup problem. AI generates verbose, defensive code because its training data rewards coverage over elegance. A WordPress codebase that would run 4,000 lines under human authorship balloons to 12,000-15,000 lines with AI assistance. Every extra line is a line someone has to read during the next bug fix.
Organization fragmentation means each developer on your team has a private relationship with their AI tool, complete with different prompt strategies, different context windows, and different model versions. There's no shared "how we write WordPress code" standard because each person's AI assistant enforces its own implicit standard.
This triad maps directly to the hidden cost architecture of technical debt that compounds across client portfolios. One bloated theme is a nuisance. Thirty bloated themes is a margin crisis.
Every Developer's Agent Makes Different Decisions
The specific mechanical failure that turns AI code generation into an agency-wide problem is standardization, or the lack of it. A full 39% of engineering leaders worry about shipping with confidence as AI agents write more code, and the root cause traces to how these tools receive (or don't receive) project-specific context.
Brian Owens of Keypress Software Development Group put it directly: AI tools "will occasionally ignore key aspects of the existing codebase or fail to align with established coding standards, creating additional work for teams in the form of review, refactoring, and rework to ensure production readiness."
That rework is invisible until it's expensive. A white-label partner ships a WooCommerce checkout customization. Your in-house developer modifies it three weeks later. The AI-generated code uses a different enqueueing pattern, a different naming convention for custom hooks, and wraps everything in a class structure your team doesn't use anywhere else. The modification that should take 20 minutes takes 90, because 70 of those minutes are spent reading and understanding someone else's AI's architectural preferences.
The modification that should take 20 minutes takes 90, because 70 of those minutes are spent reading someone else's AI's architectural preferences.
Project-level rules offer the preventive fix. These are persistent instruction files that tell AI agents which patterns to follow, which functions to use, which naming conventions to enforce. The teams getting this right treat AI constraints documents the way they treat coding standards: as mandatory reading before any code gets written. A good constraints document specifies things like "no N+1 queries," "use WordPress transients for caching instead of custom solutions," "register all custom post types through a single factory class." Without that document, every prompt is a blank slate, and every blank slate produces a different answer.
Agency Code Review Standards Were Built for Human Output
The WordPress contributor handbook defines a review hierarchy: code should be Correct, Secure, Readable, Elegant, and Altruistic, in that order of priority. AI-generated code typically passes the first two checks with flying colors. It compiles (correct) and it avoids obvious injection vectors (secure). It fails hard on readable, elegant, and altruistic.
Readable means a developer unfamiliar with the code can understand it without external documentation. AI-generated WordPress code is readable line-by-line but incoherent file-by-file, because each function was generated in a context window that didn't include the surrounding architecture.
Elegant means the solution uses the simplest approach that fully solves the problem. AI defaults to the most common approach in its training data, which is the most verbose approach, because training data skews toward tutorials and Stack Overflow answers written for beginners who need every step spelled out.
Altruistic means the code considers future developers who will modify it. AI-generated code breaks most visibly here because it has no concept of who comes next or what they'll need to change. Every function is a self-contained unit written for an audience of one: the person who prompted it.
Agencies that treat their white-label partners as genuine development collaborators rather than ticket-processing vendors have an advantage here. Code review checklists adapted for AI output need three additions that traditional checklists skip: pattern consistency checks (does this PR match the architectural patterns used in the rest of the codebase?), duplication audits (has the AI re-implemented logic that already exists?), and dependency verification (did the AI introduce a library or framework that nobody agreed to use?).
Warning: If your code review checklist was written before your team adopted AI assistants, it's checking for the wrong failure modes. AI code passes syntax and security reviews with ease. The real failures are architectural.

The Maintenance Multiplier Across Client Sites
One agency reported reducing bug reports by 67% after implementing AI-powered automated testing. That number is real, and it's also misleading when applied to the maintenance problem. Automated testing catches functional regressions: buttons that stopped working, forms that don't submit, pages that throw 500 errors. It doesn't catch the structural drift that makes a codebase expensive to work on six months from now.
The maintenance multiplier works like this. A white-label agency manages 30 client WordPress sites. Developers use AI assistants on all of them. Each site accumulates 20-30% more code than necessary (the bloat vector). Each site has 2-3 conflicting architectural patterns (the fragmentation vector). When a security patch requires touching custom code across those 30 sites, the time-per-site doubles because every site is a unique tangle of AI-generated patterns that nobody fully understands.
As LeadDev reported, the growing frequency of copy-and-pasted lines in AI-assisted commits has the potential to dramatically escalate technical debt. For white-label agencies, this debt doesn't live in one repo. It replicates across every client site your team touches, and it compounds every month that passes without a thorough architecture audit.
Where the Model Breaks
The mechanism described above has a failure point that no amount of process can fully resolve: AI code generation is stateless across sessions. Even with project-level rules, even with constraints documents, even with rigorous code review, AI assistants don't learn from the corrections your team makes. The same developer using the same tool will hit the same architectural mismatch tomorrow that they corrected today, because the model doesn't retain context between conversations.
This means AI code generation WordPress workflows succeed for isolated, well-specified tasks: a single shortcode, a specific REST API endpoint, a targeted WooCommerce filter. The approach breaks down when the output needs to fit coherently into a larger system that evolves over months. And white-label WordPress delivery is, by definition, a long-running system that evolves over months and years across dozens of client sites.
The agencies navigating this successfully aren't banning AI tools. They're building the scaffolding around those tools: constraints documents, pattern libraries, adapted code review checklists, and mandatory architecture alignment checks. All of that compensates for what AI fundamentally cannot do on its own: remember what your team decided yesterday and build on it today. The tooling saves time. The scaffolding saves the codebase.