
Every white-label WordPress engagement starts with the same optimistic Slack channel: introductions, shared Trello or Asana boards, a kickoff call where everyone agrees on timelines. Within six weeks, the channel goes quiet. The agency's project manager posts updates in one thread. The development team tracks progress in a separate tool. The client-facing strategist improvises answers because nobody tagged her on the staging link. The silo didn't form because anyone chose it. The silo is what happens when white-label collaboration workflows have no enforceable rules.
A Harvard Business School working paper analyzed roughly 360 billion Outlook emails across more than 4,300 organizations and found that remote and distributed teams become measurably more modular over time. Communication within teams intensified, but cross-team interactions dropped. The researchers noted that the medium of communication itself changed who communicates with whom. If that's true inside a single company, imagine what happens when your agency contracts an entirely separate dev team in a different time zone, using different project management conventions, operating under a different set of incentives.
These six rules won't eliminate friction. They will, however, prevent the most common forms of outsourcing communication breakdown that kill white-label partnerships before the first site launches.
Define ownership before you assign a single task
The most destructive pattern in agency team integration is ambiguity about who owns what. Role confusion doesn't surface during kickoff calls. It surfaces three weeks later, when the client asks for a WooCommerce checkout customization and nobody can say whether that request belongs to the agency's internal team, the white-label developers, or the freelancer who handled the original design.
Clear task delegation, as 51 Blocks notes in their best practices research, reduces overlaps and gaps in the workflow. But "clear" doesn't mean "discussed once on a call." It means written down in a shared document that both teams reference weekly. Spell out who handles scope changes, who has staging access, who communicates with the client, and who decides when a task is done versus when it needs revision.
This applies at every level. If your agency also contracts Shopify developers for e-commerce builds alongside your WordPress white-label team, the ownership map needs to cover platform boundaries too. Which team handles shared integrations like payment gateways? Who owns the DNS cutover? Write it down or watch the silo form around whoever answers email fastest.

Never let a handoff happen without a shared artifact
Handoffs are where collaboration dies. Designer finishes a comp, drops it into a folder, pings a developer. Developer interprets the comp differently than intended, builds something close but not right, submits it for review. The agency PM catches the mismatch two days later and files a revision ticket. Two more days pass. We've covered how the design-to-code bottleneck costs agencies real hours, and the root cause is almost always a handoff with no shared artifact.
A shared artifact is a single document, board, or annotated prototype that both the sender and receiver reference during the transition. It could be a Figma file with developer annotations. It could be a Loom video walking through the expected behavior. It could be a one-page brief in Notion that lists every interactive state, every conditional element, every edge case the designer already thought through.
The format matters less than the principle: if the handoff relies entirely on a Slack message and a link, information will get lost. Every. Single. Time. Build the artifact creation step into your project template so it's a checkbox, not a suggestion.
Treat async communication as architecture, not a convenience
Async development bottlenecks destroy white-label partnerships faster than bad code. When your agency operates in Eastern time and your dev partner works from Southeast Asia, you have a four-to-five-hour overlap window at best. If your collaboration model depends on real-time conversation to resolve blockers, every unresolved question costs you a full calendar day.
The fix is to design your async workflows as real infrastructure. That means structured daily standups posted asynchronously in a dedicated channel, with a standardized format: what was completed, what's blocked, and what decisions need input before the next work session. It means pre-writing decisions in shared docs instead of debating them in meetings. It means giving developers enough context in every ticket that they can work autonomously for eight hours without needing to ask a clarifying question.
Agencies that have moved beyond ticket-based models that stall at scale typically land on a hybrid: async by default, with one or two synchronous touchpoints per week reserved for blockers that genuinely require a live conversation. The ratio matters. If more than 30% of your collaboration happens synchronously, your white-label team will spend more time waiting than building.
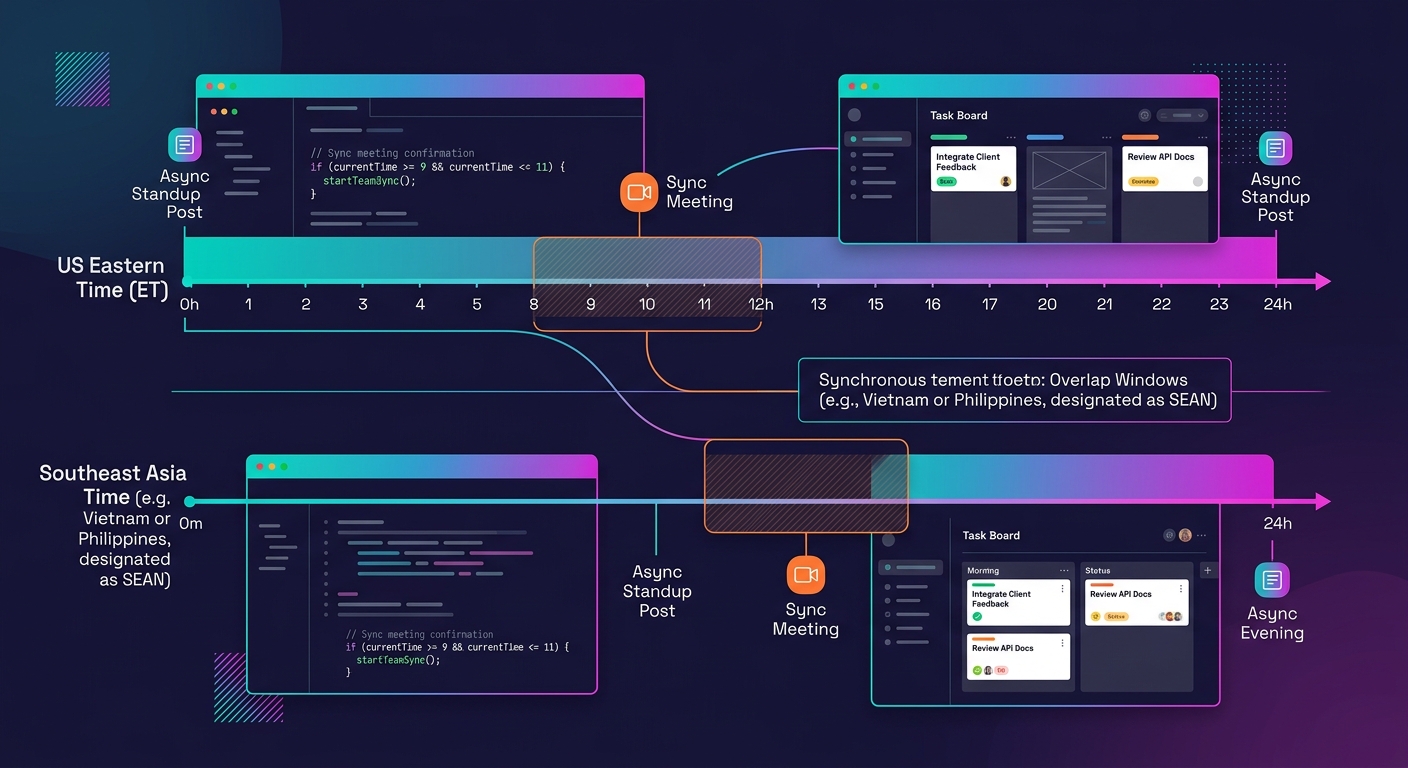
Tip: Create a "decision log" document for each active project. Whenever a question gets resolved in Slack or a call, someone writes the decision and the reasoning into the log within 24 hours. This single habit prevents the most common async failure: the answer that existed but nobody could find.
Make capacity visible across every team boundary
A CMSWire analysis found that implementing tools providing visibility across departments is the single highest-impact change organizations make when breaking down silos. One consulting firm reported a 76% productivity increase after making team workloads visible across groups.
For agencies, visibility means your project manager can see, at a glance, what your white-label team is working on, what's queued, and what capacity looks like for the week ahead. And it means the white-label team can see which client requests are coming down the pipeline so they can plan accordingly.
This doesn't require expensive software. A shared Asana or Monday.com board, updated daily, works. A weekly capacity snapshot posted in Slack works. What doesn't work is each team maintaining its own internal tracker and then manually relaying status updates. That relay is where information distorts, timelines slip, and both sides start blaming each other for missed deadlines.
If your white-label collaboration workflows include multiple service teams, the visibility challenge multiplies. We've written about why outsourcing models fracture at scale and the systems thinking required to hold them together. Capacity visibility is the connective tissue. Without it, every team optimizes locally while the overall project drifts.
The silo didn't form because anyone chose it. The silo is what happens when collaboration has no enforceable rules.
Run cross-team retrospectives on a fixed calendar
Most agencies run retrospectives internally. Almost none include their white-label partners. This is a mistake, and it's the mistake that cements silos into permanent structures.
A quarterly cross-team retrospective where both the agency side and the dev partner openly discuss what's working, what's failing, and what needs to change is the single cheapest intervention with the highest return. The format can be simple: each side prepares three items they want to keep, three they want to change, and one question they've been afraid to ask.
That last category is where the real value lives. White-label teams often notice patterns they don't feel empowered to raise. Maybe every project from your agency arrives with incomplete content. Maybe your QA feedback is vague and contradicts itself. Maybe your staging environment keeps breaking because nobody updates the plugins. These are solvable problems, but they stay invisible until someone creates a structured space to surface them.
And the cadence matters. Annual reviews are too infrequent to catch drift. Monthly feels heavy for teams already juggling client deadlines. Quarterly hits the sweet spot: often enough to course-correct, infrequent enough that each session carries weight. The research on feedback loops versus ticket queues in outsourced WordPress teams supports this cadence, showing that structured feedback intervals outperform ad-hoc complaint cycles.
Give your white-label partner the same context you'd give an internal hire
Here's the uncomfortable truth about most agency-to-white-label relationships: agencies share tasks but withhold context. The dev team gets a ticket that says "Build a custom post type for case studies" but never learns why the client needs case studies, what the broader marketing strategy looks like, or how this piece fits into the site's conversion goals.
When your internal designer builds a landing page, they've absorbed weeks of client conversations, brand guidelines, competitor analysis, and strategic direction. They make a hundred small decisions correctly because they understand the intent behind the request. Your white-label developer, receiving a bare Asana card, makes those same decisions by guessing. Some guesses land. Many don't. Every wrong guess becomes a revision cycle.

The fix is straightforward: create a project context brief for every engagement. Include the client's business goals, target audience, competitive landscape, brand voice, and any past decisions that constrain the current build. Share it with the white-label team before the first sprint. Update it when the strategy changes. Treat your external dev team as collaborators who need to understand the "why," and they'll deliver work that requires far fewer revisions.
This is the difference between a white-label team that executes tickets and one that genuinely integrates with your agency's output. The context brief takes 30 minutes to write. It saves days of back-and-forth.
When These Rules Break Anyway
They will. A client will drop an emergency redesign request at 4 PM on a Friday, and your carefully structured async workflow will collapse into frantic Slack messages across three time zones. A key developer on the white-label side will leave mid-project, and all the ownership documentation in the world won't prevent a two-week knowledge gap. Your quarterly retrospective will get pushed "just this once" and then not happen for seven months.
The value of having these rules isn't that they prevent every collaboration failure. It's that they give you a known-good state to return to after the chaos passes. Without them, every crisis response becomes the new normal, and the silo deepens.
And some silos aren't worth breaking. If your white-label team handles WordPress maintenance while a separate internal team runs paid media, those groups may genuinely have no reason to collaborate day-to-day. Forced collaboration wastes time just as badly as accidental isolation. The research from Harvard's email analysis backs this up: intra-team focus can boost output and morale when the boundaries are intentional and the interfaces between teams are well-defined.
The rules above target the other kind of silo: the one that forms quietly, costs you days per project in revision cycles and miscommunication, and gradually erodes trust between your agency and the partner you're supposed to be building with. Fix the rules first. The collaboration follows.